Deep Learning
Deep Learning är ett av de hetaste ämnena inom data science och AI nuförtiden. Det är även ett av de områden som kräver mest i form av beräkningskraft och därmed behovet av GPUer. Deep learning är en specialgren av Machine Learning som kort går ut på att genom att ge maskiner tillgång till data och låt dem lära sig själva. Machine Learning i sin tur är “state of the art” inom AI - Artificiell intelligens, ett område som funnits sedan 1950-talet. Med AI menar vi att maskiner kan utföra och lösa uppgifter på ett sätt som vi uppfattar som “smart”.
Machine Learning i sig behöver inte innebära att man behöver speciella GPU-kluster. Det som avgör är vilken typ av data man arbetar med. Är datan strukturerad som i till exempel databastabeller, kalkylark eller semi-strukturerad som data för statistisk analys (IID), kan det räcka utmärkt med vanliga CPUer som är betydligt billigare i inköp.
Är datan å andra sidan ostrukturerad, som till exempel bild, röst eller textdata så krävs det helt andra metoder.
Neural Networks
Det som gör Deep Learning speciellt är att man använder sig av neurala nätverk med algoritmer som är inspirerade av den mänskliga hjärnan. Dessa nätverk är uppbyggda av lager av neuroner som är själva beräkningsnoderna i nätverket. Man skulle kunna beskriva det som en matematisk representation av hjärnan där varje nod motsvarar en biologisk neuron.
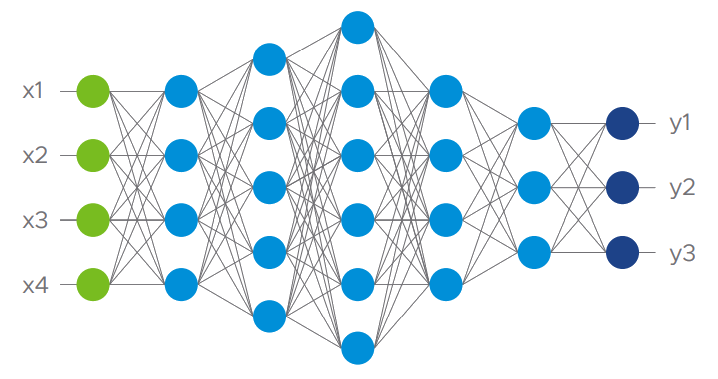 Neural Network1
Neural Network1
Utvecklingen av neurala nätverk startade redan på 1940-talet just som en modell för att simulera hur neuroner skulle tänkas fungera. Då använde man elektriska kretsar men när man började använda datorer tog utvecklingen fart. Bland annat så införde man en viktad beräkningsmodell för att propagera signaler genom nätverket och man gjorde nätverket i sig flera lager djupt. Men det stora intresset för neurala nätverk uppstod när man introducerade en algoritm för så kallad backpropagation. Den gjorde det möjligt att träna nätverk för att lösa uppgifter.
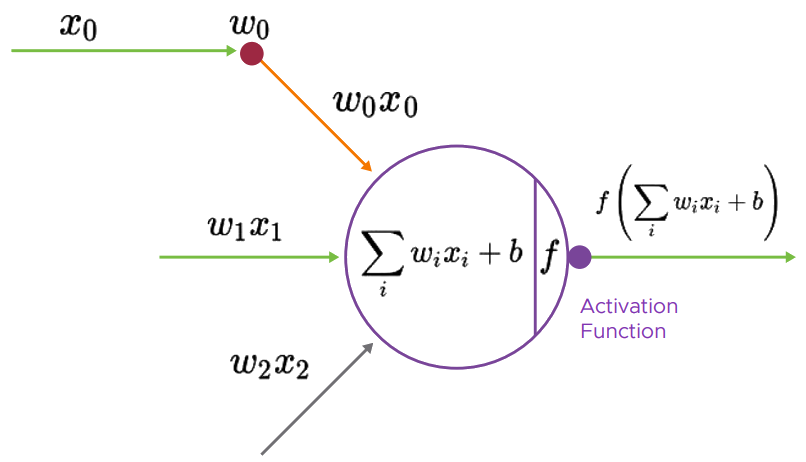 Nodberäkning1
Nodberäkning1
All inputdata, oavsett om det är bild, röst eller text, konverteras till ett numeriskt värde. Dessa värden matas sedan in i inputlagret (det gröna i nätverksbilden ovan). I varje nod sker sedan en beräkning likt nodberäkningsbilden och resultet flödar vidare genom lagren i modellen åt höger. När flödet når sista lagret i modellen vänder processen genom så kalla backpropagation för att “träna” systemet och modellen mot önskat resultat.