Latency vs. Throughput
Jämför man arkitekturen för en CPU med en GPU så ser man tydliga skillnader. 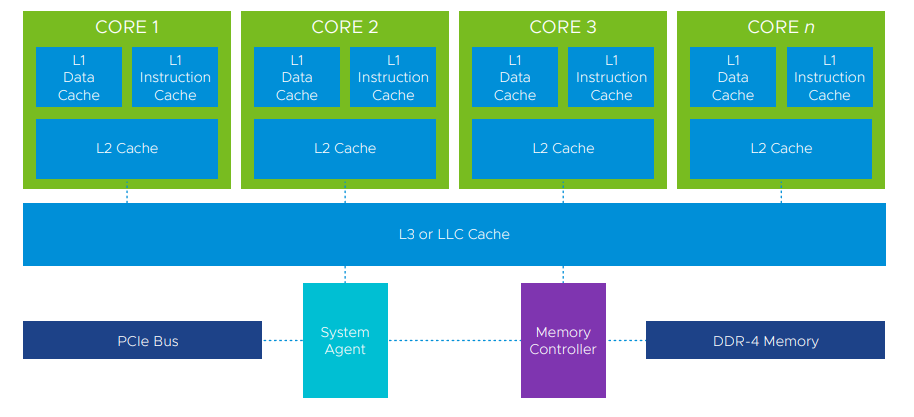 CPU Architecture1
CPU Architecture1
En CPU är optimerad för att snabbt avsluta operationer och kunna hoppa mellan dem. För att klara det strävar man efter att ha så låg latency som möjligt för L1 och L2 Cache. 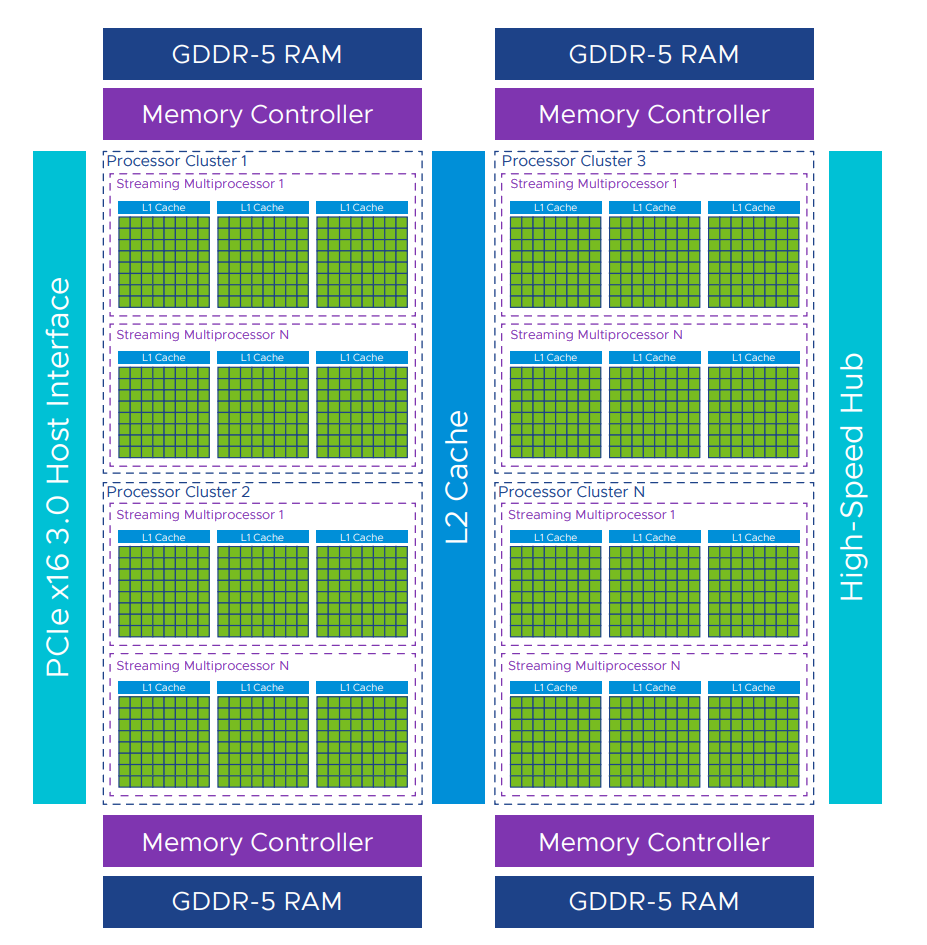 GPU Architecture1
GPU Architecture1
För en GPU är fokus på Throughput vilket man åstadkommer genom att utföra många operationer parallellt. Istället för minnescache med låg latency så ligger kraften i förmågan att hantera stora mängder beräkningar.
När vi ser på fallet med Deep Learning är det uppenbart att ju fler beräkningar vi kan göra parallellt, desto snabbare kommer vi att uppnå ett resultat.
GPU skala vertikalt, eller horisontellt
Att använda GPUer är kostsamt så det gäller att anpassa infrastrukturen efter behov. Om man utgår från en GPU kan man skala neråt genom att dela upp denna i fraktioner och dela dessa mellan olika jobb. Behöver man mer kraft kan man skala uppåt genom att skaffa kraftfullare GPU. Slutligen kan man skala ut och dela upp jobbet på flera processorer över flera hostar genom att använda Horovod, ett open source projekt som är en del av Linux Foundations AI innovation.
Konceptuell beskrivning av vertikal kontra horisontell skalning av GPU